
Service-Katalog
Nutzen Sie Innovation Services aus unserem Katalog, um eigene datengetriebene Innovationen zusammen mit deutschen Spitzenforschern umzusetzen.
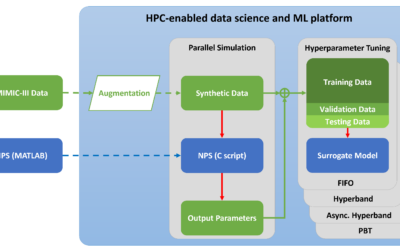
Verbesserung von KI-Modellen mit Hyperparameter-Tuning
Hyperparameter Tuning (oder Hyperparameteroptimierung) ist ein wichtiger Schritt im Prozess der Entwicklung und Optimierung künstlicher Intelligenz (KI Modell). Hyperparameter...
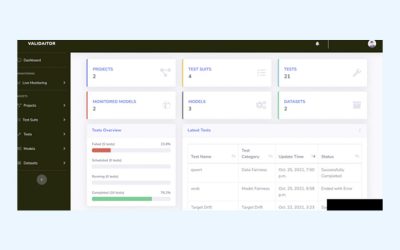
Modellverifikation und -Testung für vertrauenswürdige KI
Maschinelle Lernalgorithmen werden auf lediglich auf die Genauigkeit auf Testdaten verglichen. In der Realität gibt es jedoch deutlich mehr Maße, um die Robustheit einer...

Physical Intelligence: Kopplung von physikalischen und KI-basierten Modellen für Regression, Interpolation und Optimierung
Simulationen können komplexe ungesehene Phänomene vorhersehen, während maschinelles Lernen insbesondere bestehende Beobachtungen generalisieren kann. Beide Arten des...
Kognitive große Sprachmodelle für konversationelle KI-Assistenten
Trotz der Aufregung um Large Language Models (LLM) leiden diese Modelle unter Illusionen, d.h. sie erzeugen faktisch falschen Text. Diese Probleme schränken die Entwicklung von...
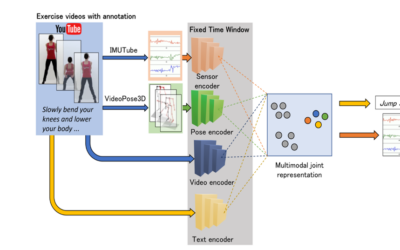
Sensorbasierte, multimodale Modelle zur Aktivitäts- und Bewegungserkennung aus Videodaten
Sensorbasierte Erkennung von Bewegungsmustern und Aktivitäten erlaubt die automatisierte Beurteilung von Fitnessaktivitäten. Hierbei verwenden multimodale Modelle Informationen...

Human AI Interaction
In der sich ständig weiterentwickelnden Landschaft der künstlichen Intelligenz (KI) ist es entscheidend, neue Ansätze für die Darstellung und Interaktion mit KI-Modellen zu...
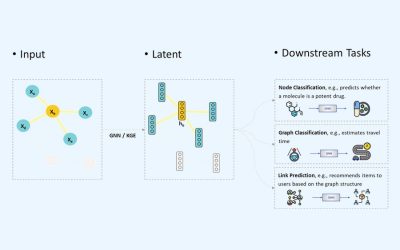
Deep Learning auf Wissensgraphen für den Aufbau kognitiver Unternehmensdienste
Die meisten Daten aus Unternehmen können in einem Knowledge Graph abgebildet werden. Daten aus dem Tourismus, von Lieferketten oder aus dem Gesundheitswesen lassen sich als...

Federated Learning in der Medizin
Medizinische Daten werden im Alltag in Krankenhäusern und im Gesundheitssektor generiert und gespeichert. Aus Datensicherheits- und Datenschutzgründen ist die Verwendung solcher...
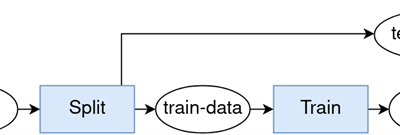
PipesAI: Strukturierung und Ausführung von ML-Trainingspipelines und deren Versionierung

PipesAI ist eine leichtgewichtiges Python-Framework, welches eine einfache Möglichkeit zur Erstellung von Pipelines für Datenverarbeitungs- und Analyseaufgaben bietet. Es...

LWM – Large Whatever Models – mehr als nur ChatGPT
Das DFKI bietet die neusten State-of-the-Art Methoden aus der Spracherkennung gepaart mit Sensoren oder anderen Methoden an.
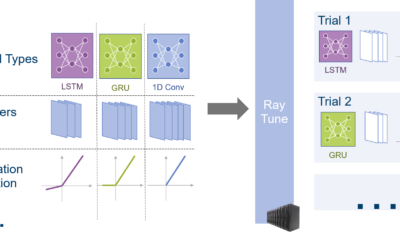
AI-Erfolg in der Gesundheitsversorgung mit Hyperparameter Tuning
Insbesondere in der Medizin und im Gesundheitssektor ist es besonders relevant, das beste Ergebnis aus Modellen des maschinellen Lernens (KI-Modelle) herauszuholen....

KI-gestützte Bild- und Videoverarbeitung
Unser Service Wir bieten Ihnen einen umfassenden Service zur Entwicklung und Optimierung von KI-Modellen für die Bild- und Videoverarbeitung. Dazu gehören die Auswahl, das...

Fusion von Multimodalen Maschinellen Lernverfahren
Das DFKI bietet State-of-the-Art Methoden aus der Sprach- und Videoerkennung gepaart mit Sensoren oder anderen Methoden an. Dies ermöglicht die Erzeugung von individuellen...
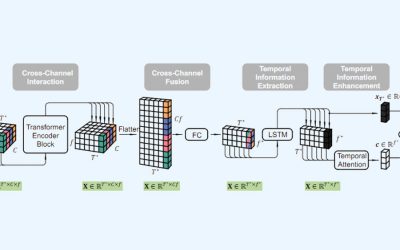
Neural Architecture Searches zur Mehrziel-Optimierung von Regressions- und Klassifikationsmodellen
Das KIT optimiert ihre existierenden kleinen und großen neuronalen Netzwerke und passt existierende Architekturen semiautomatisch auf ihre Bedürfnisse an. Der Entwurfsraum für...
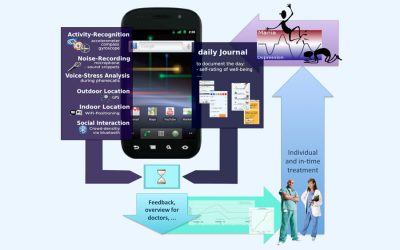
Nicht-invasive Bewertung von Fitness/Gesundheitsparametern
Das DFKI stellt diverse F&E Expertise zur Verwendung von statistischen Methoden (machine learning, deep learning, etc.) zur Analyse und Bewertung von Fitness- und...

Aktives Lernen mit Benutzerinteraktion: Skalierbare Systeme für interaktive Modellverbesserung
ChatGPT hat eindrucksvoll gezeigt, wie das Lernen von Auswahlstrategien auf Basis von menschliches Feedback die Performance von Sprachmodellen verbessern konnte (bei der...
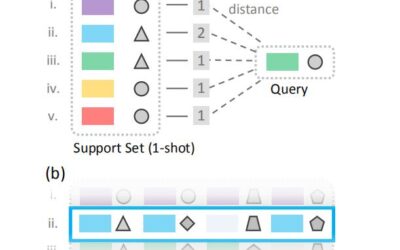
Few Shot Learning in der Medizin – Lernen mit kleinen Datenmengen
Eine große Schwäche von herkömmlichen Methoden des maschinellen Lernens ist die große Menge an Daten, die für das Trainieren benötigt werden. Das Few Shot oder One Shot Learning...
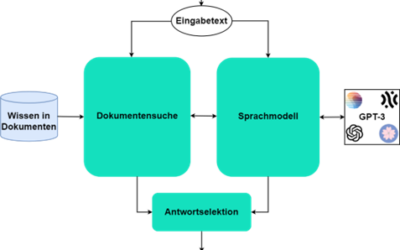
Domänenspezifischer Einsatz von Großen KI-Sprachmodellen mittels Retrieval-augmented Generation (RAG) in industriellen Anwendungen
Große vortrainierte KI Sprachmodelle (LLMs) zeigen erstaunliche emergente Fähigkeiten, die sich für eine Vielzahl von industriellen Anwendungen nutzen lassen. Das Weltwissen ist...

Anpassung großer Sprachmodelle mit Unternehmensdaten
Fraunhofer IAIS arbeitet mit Partnern aus der deutschen Industrie zusammen und unterstützt sie bei der Einführung von LLMs unter Verwendung von Unternehmensdaten und bei der...
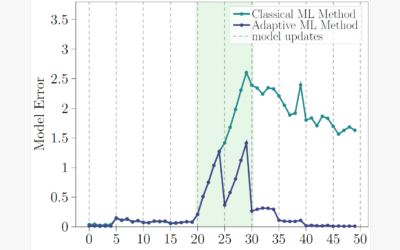
Adaptive ML-Modelle für sich ändernde Prozessbedingungen im industriellen Kontext
Durch maschinelle Lernverfahren erstellte Modelle verlieren ihre Gültigkeit, wenn sich die statistischen Eigenschaften der Eingabedaten, auf denen sie operieren, ändern. Solche...
Datensparsames, Maschinelles Lernen + Few Shot Learning
Insbesondere im Bereich High-Performance Computing haben wir Erfahrungen im Bereich Hyperparameter Tuning um KI Modelle zu verbessern und in der Parallelisierung und dem Speed-Up...
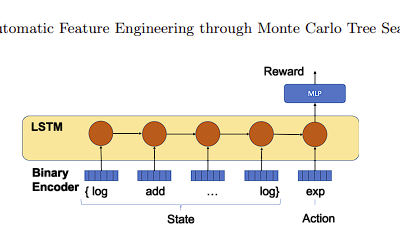
Parallelisiertes Lernen von Merkmalsräumen für große Log- und Zeitreihendatensätze
Neuronale Netze können heute oft auf Basis von Rohdaten lernen. Jedoch gibt es viele Gründe dafür die Phase der Merkmalsextraktion getrennt zu betrachten. Zum einen kann dies das...